![]()
|
Inicio
1 2
3 4 5
6 7 8
9 10 11
12 13
14 15
16 17
18 19 20
21
22 23 24
25
Activar HierarchicalCluster y preparar de datosPara activar los procedimientos en la biblioteca HierarchicalCluster, descritos en la sección anterior, se debe transmitir la siguiente orden, la cual activa también los procedimientos correspondientes a Covariances, Inertias y Dissimilarity:
La lectura de datos del problema supone que PUAucr.dat es
una archivo tipo texto, formado por 50 renglones y 5 columnas de
números separados por espacios en blanco, que contiene la tabla de
datos y está en la carpeta
El resultado de la lectura de PUAucr.dat es una matriz
El arreglo de disimilitudes, correspondiente a las 50 UA, se
determina a partir de esta tabla Y utilizando el índice de
disimilitud demoninado VarianceInverse, o sea,
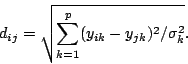
La siguiente orden calcula dicho arreglo y lo denomina d1.
|
Revista Virtual Matemática, Educación e Internet
Derechos Reservados